I sometimes need a function, and want it to be both weird and sexy. To define this function, I want to be unstructured, I don’t want to limit my imagination. I want to be able to define a set of ordered points, and then have a function that when plotted, its graph passes through them. But I need more than just being able to plot the function, I need to know its exact expression, so that I can use it later. Can we do that? That is, can we find a closed form to express such a function?
And as Obama would have said many years ago, yes we can! Given $n + 1$ points, there exists a polynomial of degree $n$ that meets this condition. Not that I particularly wanted a polynomial, but I can settle with that. The idea sounds more sexy the moment you are told that there is a unique polynomial of degree $n$ complying with such constraints.
Do you want to find it? I want. Let’s go!
A poly-what?
A polynomial of degree $n$ is a function $P(x)$ that can be written as
\[P(x) = \sum_{k = 0}^{n} a_k x^k = a_0 + a_1 x + a_2 x^2 + \ldots + a_n x^n\]The set $\left\{a_0, a_1, \ldots, a_n\right\}$ are the coefficients of the polynomial. As the values of these coefficients change, we obtain a different polynomial each time.
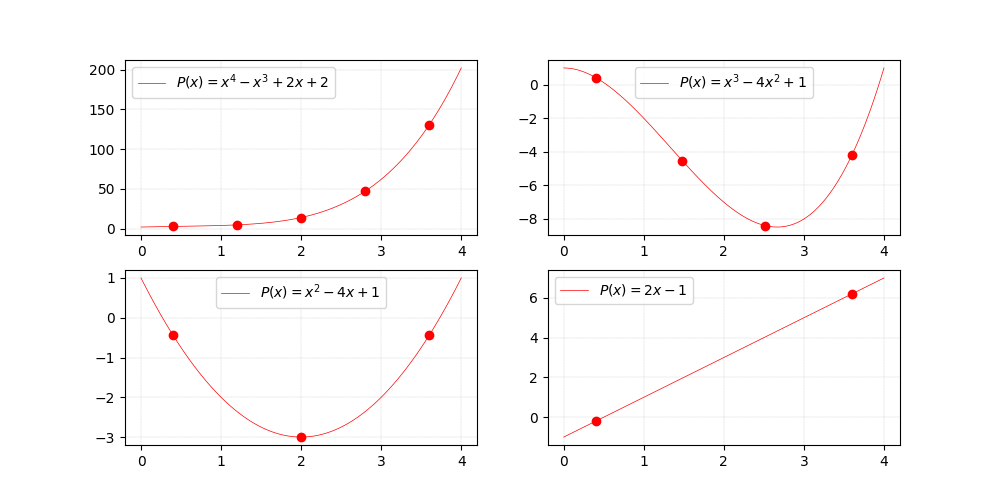
Polynomials of $x$.
If we plot $P(x)$, the exact shape of the curve we obtain depends on the coefficients of the polynomial, as shown on the figure on top.
A system of equations
Our problem is finding the coefficients’ values for which the graph of $P(x)$ indeed traverses the requested $n + 1$ points.
And what can we do to find them? Well, the points need to be in the image of $P(x)$. That is, for each point $(x_j, y_j)$ in the set, we know that $P(x_j) = y_j$ must hold. As we have $n + 1$ points, evaluating $P(x)$, we can create a system of $n + 1$ equations.
\[\begin{align} P(x_0) &= a_0 + a_1 x_0 + a_2 x^2_0 + \ldots + a_n x^n_0 = y_0 \\ P(x_1) &= a_0 + a_1 x_1 + a_2 x^2_1 + \ldots + a_n x^n_1 = y_1\\ &\;\;\vdots \notag \\ P(x_n) &= a_0 + a_1 x_n + a_2 x^2_n + \ldots + a_n x^n_n = y_n\\ \end{align}\]To find the answer to our problem, we need to solve the system.
Things look good a priori, as in general we can only find the values of $n + 1$ unknowns (the coefficients) if we have the same number of equations.
Bring on the matrices
We switch to matrix notation and define
\[\mathbf{X} = \begin{bmatrix} 1 & x_0 & \cdots & x^n_0 \\ 1 & x_1 & \cdots & x^n_1 \\ \vdots & \vdots & & \vdots \\ 1 & x_n & \cdots & x^n_n \\ \end{bmatrix}\quad \mathbf{a} = \begin{bmatrix} a_0 \\ a_1 \\ \vdots \\ a_n \\ \end{bmatrix}\quad \mathbf{y} = \begin{bmatrix} y_0 \\ y_1 \\ \vdots \\ y_n \\ \end{bmatrix}\]so that then we can describe our problem more compactly as
\[\mathbf{X} \cdot \mathbf{a} = \mathbf{y}\]In particular, $\mathbf{X} \in \mathbb{R}^{(n+1) \times (n+1)}$ is not just any other square matrix, it is actually known as the the Vandermonde matrix.
A solution, but not THE solution
Thanks to good old Algebra, after switching the notation, we see that in the end, the solution is to simply get
\[\mathbf{a} = \mathbf{X}^{-1} \cdot \mathbf{y}\]End of story? Well…just hold on to your belts!
First, we should ask ourselves whether $\mathbf{X}^{-1}$ even exists. As $\mathbf{X}$ is a square matrix, it could indeed be the case. In fact, I am sure there is a proof for this, but just looking at the expression, you can already tell that the inverse of this matrix exists as long as $\forall j \neq k,\; x_j \neq x_k$. That is, there should not be two points requesting some image for the same domain value.
Say we had $(x_p, y_a)$ and $(x_p, y_b)$ in our set of points. If $y_a \neq y_b$, then the problem would be messed up from scratch: a well-defined function can only have a unique image per domain element. If instead $y_a = y_b$, then we would have a point that repeats in our set, and we would only have be able to construct $n$ linearly independent equations. In this case, rather than a unique polynomial of degree $n$, the solution would consist of a sub-space of polynomials.
Second, to compute $\mathbf{X}^{-1}$, how much computational power do we need? Again without proof, but without doubts neither, I’m sorry to break it to you, me, and everyone else, but computing this matrix is an $O(n^3)$ operation…so as soon as $n$ becomes of a moderate value, good luck waiting for that to run!
Fortunately, Lagrange came to the rescue and saved us all.
Lagrange Interpolation
Lagrange changed a little bit the way we were thinking about the problem, and proposed to think the polynomial $P(x)$ as the sum of $n + 1$ functions
\[P(x) = \sum_{i=0}^{n} \alpha_i \phi_i(x) = \alpha_0 \phi_0(x) + \alpha_1 \phi_1(x) + \ldots + \alpha_n \phi_n(x)\]and then proved that the solution was to define
\[\alpha_i = y_i\] \[\phi_i(x) = \frac{\prod_{j \neq i}x - x_j}{\prod_{j \neq i}x_i - x_j}\]Analyzing the expressions, we see that $\forall j \neq i,\; \phi_i(x_j) = 0$. In addition, $\phi_i(x_i) = 1$ and as $\alpha_i = y_i$, then $\alpha_i \phi_i(x_i) = y_i$. This way, for each point $(x_k, y_k)$, out of all the functions composing $P(x)$, there is only $\alpha_k \phi_k(x)$ that evaluated at $x_k$ returns $y_k$, while the other $n$ functions are nil.
I mean…what a beast, such a clever and elegant solution. Chapeau!
The interpolation in action
Let’s analyse one case to convince ourselves! Say we want a function for the following $5$ points.
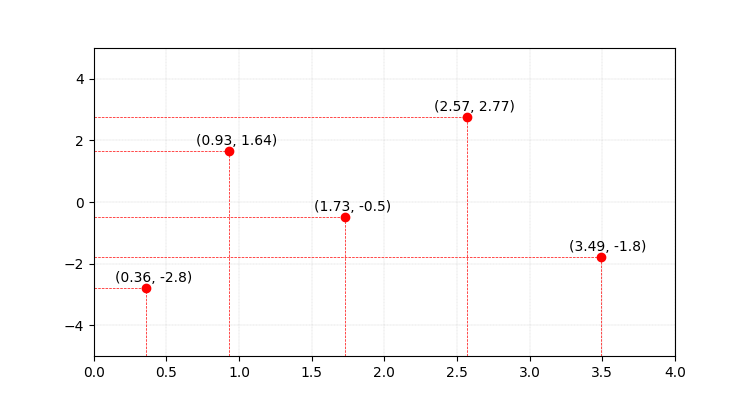
Points that must be on the image of $P(x)$.
I guess we would all panic if we are asked to solve this, but we just learned about Lagrange’s interpolation, so we know we can find the polynomial of degree $4$ that meets this condition.
In particular, let’s gather the functions that compose $P(x)$:
xx = np.linspace(0, 4, 200)
a1phi1 = -2.8 * \
((xx - 0.93) * (xx - 1.73) * (xx - 2.57) * (xx - 3.49)) / \
((0.36 - 0.93) * (0.36 - 1.73) * (0.36 - 2.57) * (0.36 - 3.49))
a2phi2 = 1.64 * \
((xx - 0.36) * (xx - 1.73) * (xx - 2.57) * (xx - 3.49)) / \
((0.93 - 0.36) * (0.93 - 1.73) * (0.93 - 2.57) * (0.93 - 3.49))
a3phi3 = -0.5 * \
((xx - 0.36) * (xx - 0.93) * (xx - 2.57) * (xx - 3.49)) / \
((1.73 - 0.36) * (1.73 - 0.93) * (1.73 - 2.57) * (1.73 - 3.49))
a4phi4 = 2.77 * \
((xx - 0.36) * (xx - 0.93) * (xx - 1.73) * (xx - 3.49)) / \
((2.57 - 0.36) * (2.57 - 0.93) * (2.57 - 1.73) * (2.57 - 3.49))
a5phi5 = -1.8 * \
((xx - 0.36) * (xx - 0.93) * (xx - 1.73) * (xx - 2.57)) / \
((3.49 - 0.36) * (3.49 - 0.93) * (3.49 - 1.73) * (3.49 - 2.57))
And let’s just plot and see how these functions look like.
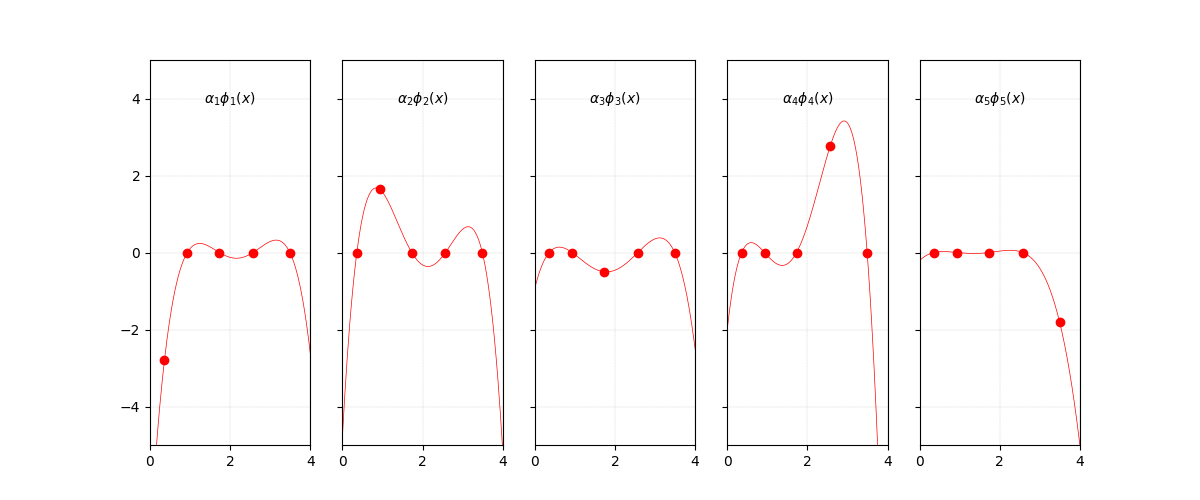
Functions that compose $P(x)$.
The first feeling when you look at this is “oh, it will be hard to prove that this truly adds up to what we need”. But to simplify, recall that each function focuses on one point at a time, while ensuring it does not bother the other. This is why, for the points highlighted, there is only one where $y \neq 0$ and for the others $y = 0$. Things are actually looking good then!
Final step, let’s add these functions and see what we get.
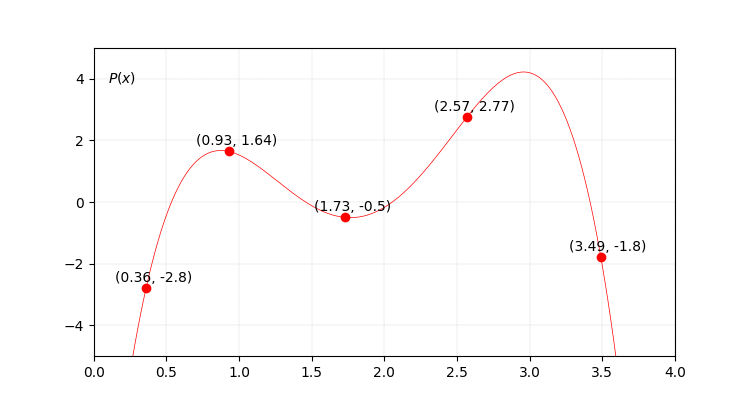
Resulting $P(x)$.
An image sometimes is worth more than a million words, so I will limit myself to simpley say beautiful.
Generalizing: any and all polyomials?!
A natural question that follows is whether we could not have found a more “compact” solution that the one that Lagrange proposed. In short, the answer is no, but let’s reason about it.
For example, if we were able to find some linear dependency among the $\phi_i(x)$ functions, removing it we could maybe come up with another solution for $P(x)$, composing it with less than $n + 1$ functions.
Well, dreaming is ok, but if that is how we come up with solutions, Lagrange clearly had very sweet dreams long ago: his solution actually conforms a basis for the space of polynomials of degree $n$ (note that this space is of dimension $n + 1$).
The fact that the set of Lagrange’s functions $\phi_i(x)$ conforms a basis means that, relying these functions:
- we can produce all the polynomials of degree $n$, and;
- for each polynomial, there is a unique combination of the $\phi_i(x)$ functions that produce them.
For example, another basis for the same sub-space is the canonical one, conformed by the functions $\left\{1, x, x^2 \ldots, x^n\right\}$, as shown below for $n = 4$.
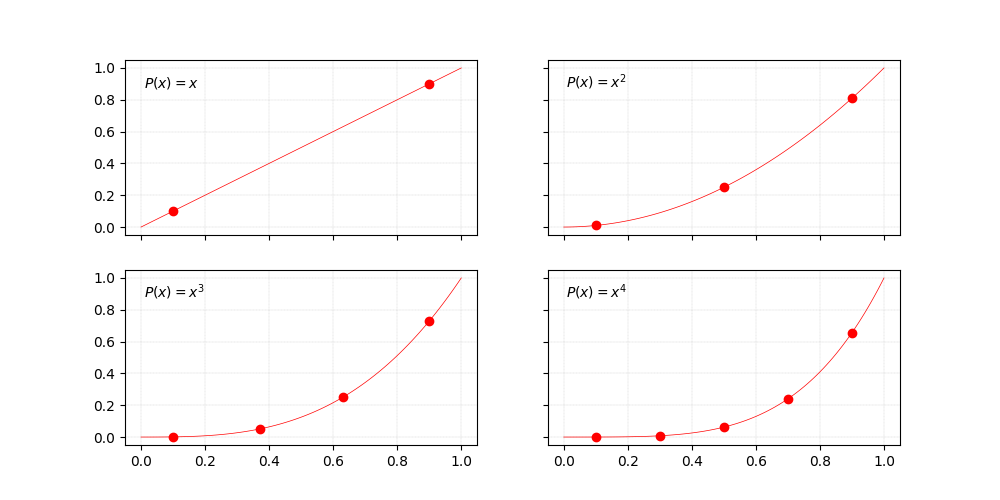
Polynomials of degree $n \geq 1$ for the canonical basis of degree $4$.
I know, if we compare the functions on the plot we just obtained for the canonical basis with the ones from Lagrange’s interpolation we calculated before, it is human to hesitate …are we sure that the very clever formulation of Lagrange is also a basis? Well, only reason can defeat fear, so let’s prove it to convince ourselves.
To verify that Lagrange’s functions conform a basis of the $n$-degree polynomials, we need to work with a linear combination these functions
\[L(x) = \beta_0 \phi_0(x) + \beta_1 \phi_1(x) + \ldots + \beta_n \phi_n(x)\]If we can show that $\forall x,\; L(x) = 0 \Leftrightarrow \forall i,\; \beta_i = 0$, then it is true.
As the aforementioned condition must hold for all $x$, then in particular it must hold for $\left\{x_0, x_1, \ldots, x_n\right\}$, the x-coordinates of the $n + 1$ points used to define the $\phi_i(x)$ functions. Without loosing generality, taking $x_0$ as an example, we can compute
\[L(x_0) = \beta_0 \phi_0(x_0) + \beta_1 \phi_1(x_0) + \ldots + \beta_n \phi_n(x_0) = 0\]but based on our previous analysis, we know that this ends up evaluating to $L(x_0) = \beta_0 = 0$. We can iterate over the $n$ remaining $x_i$ values following a similar procedure to prove that in each step $i$, we need $\beta_i = 0$ to hold. And once this is done, we just need to prove the other direction of the implication, but the proof is trivial. Hence, voila, we have proved that Lagrange’s solution is indeed a basis of the $n$ polynomial space.
We need to agree that Lagrange’s solution is simply beautiful, isn’t it?
Implementing Lagrange’s interpolation
At this point we have learned many things about Lagrange’s interpolation, but I want to address a last point: how to implement it efficiently in Python. To reason about this, let’s first write down the final expression of $P(x)$:
\[P(x) = \sum_{i=0}^n y_i \frac{\prod_{j \neq i}x - x_j}{\prod_{j \neq i}x_i - x_j}\]We can go ahead and simply